Achilles 구동하기
#develop, #ohdsi
이번에는 ACHILLES 를 구동해보자.
https://github.com/OHDSI/Achilles
접속해보면 아래와 같은 설명을 볼 수 있다.
Automated Characterization of Health Information at Large-scale Longitudinal Evidence Systems (ACHILLES)---descriptive statistics and data quality checks on an OMOP CDM v5 databases
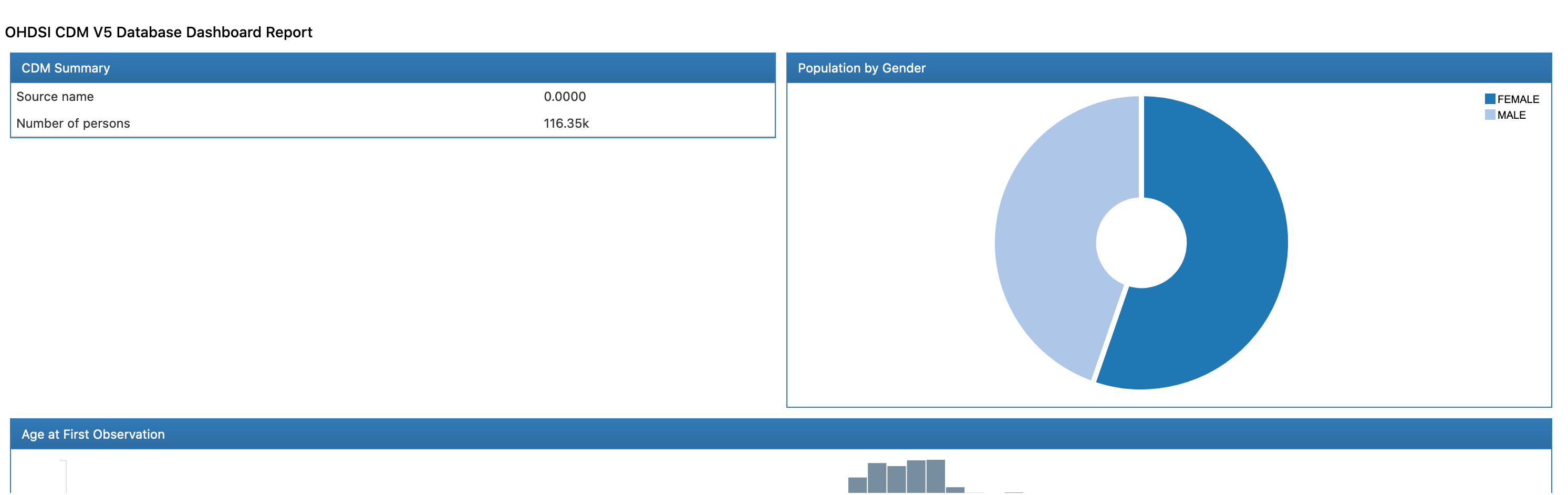
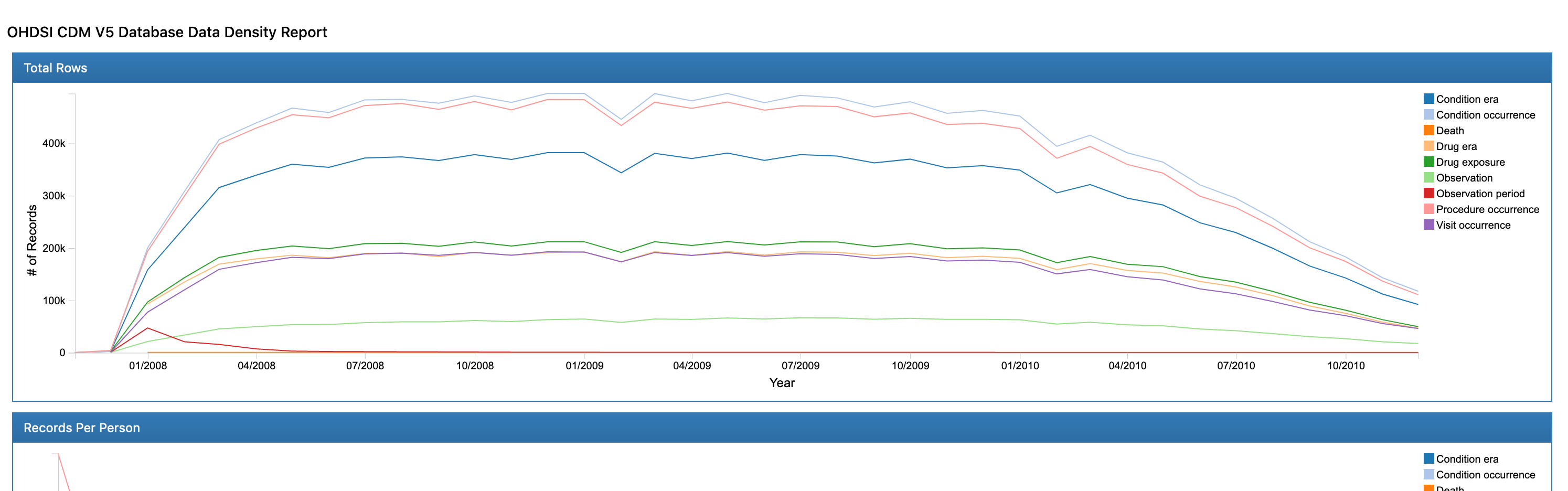
결국 이름은 거창하지만, 구축된 CDM 의 통계와 Data Quality 를 추출하는 프로젝트이다. 자세한 내용은 실행 후 결과로 확인해보자.
R 로 돌아가는 프로젝트이기 때문에 R 과 R Studio 를 설치하자. (OHDSI 의 대부분의 프로젝트는 R 을 사용하기 때문에 구축해두면 도움이 된다.)
https://github.com/OHDSI/Achilles#getting-started
위 방법을 따라 진행해보자.
if (!require("devtools")) install.packages("devtools")
library("devtools")
# To install the master branch
devtools::install_github("OHDSI/Achilles")
# To install latest release (if master branch contains a bug for you)
# devtools::install_github("OHDSI/Achilles@*release")
# To avoid Java 32 vs 64 issues
# devtools::install_github("OHDSI/Achilles", args="--no-multiarch") 설치는 생각보다 간단하다. 우선은 master branch 를 기준으로 설치한다.
Achilles 를 로딩 후 Database 정보를 입력한다.
library(Achilles)
connectionDetails <- createConnectionDetails(
dbms="postgresql",
server="server.com",
user="secret",
password='secret',
port="5432")
</code>아래와 같이 바로 구동할 수 있는데,
resultsDatabaseSchema 에 해당하는 schema 는 새로 만들어주어야 하고,
vocabDatabaseSchema 는 현재 따로 구축하지 않았기 때문에 synpuf5 를 그대로 사용하면 된다.
(vocabulary 를 따로 구축한 경우에는 그 schema 를 사용하면 된다.)
numThreads 는 환경에 따라서 변경해주면 된다.
> achilles(connectionDetails,
cdmDatabaseSchema = "synpuf5",
resultsDatabaseSchema="results",
vocabDatabaseSchema = "synpuf5",
numThreads = 1,
sourceName="SynPUF 5 percent sample",
cdmVersion = "5.2.2",
runHeel = TRUE,
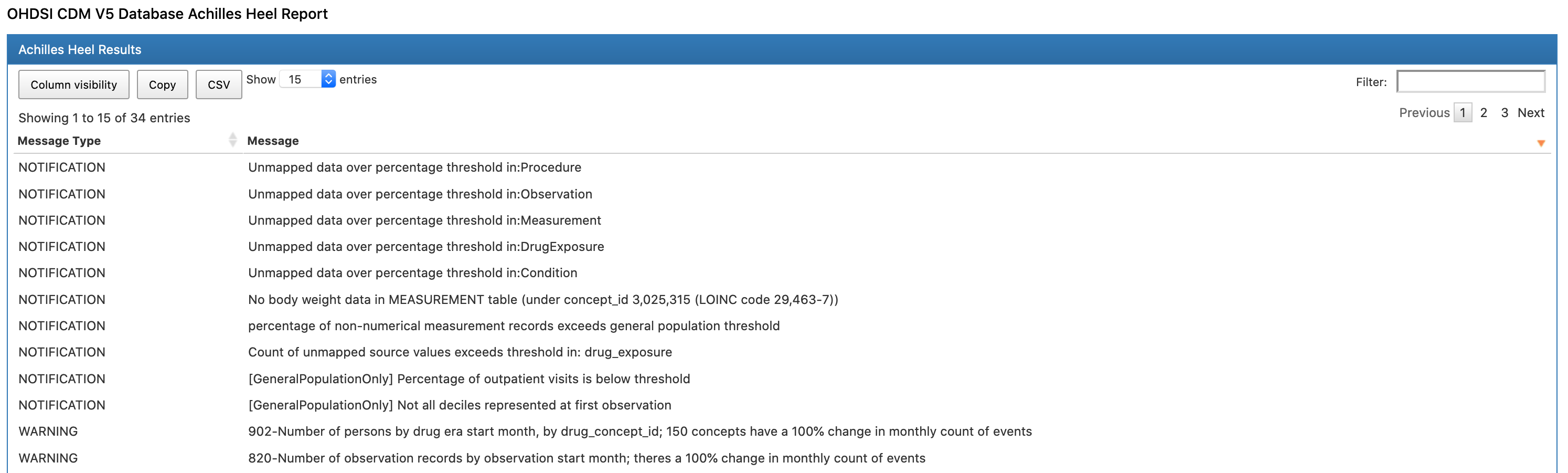
runCostAnalysis = TRUE)Warning 메세지가 몇 가지 뜨는데 내용을 하나씩 확인해보자.
Warning: Cohort table not found, will skip analyses 1700 and 1701Cohort 체크를 아래의 코드로 진행한다.
sql <- SqlRender::render("select top 1 cohort_definition_id from @resultsDatabaseSchema.cohort;",
resultsDatabaseSchema = resultsDatabaseSchema)analyses 1700 과 1701 를 살펴보자.
-- 1700 Number of records by cohort_concept_id
--HINT DISTRIBUTE_ON_KEY(stratum_1)
select 1700 as analysis_id,
CAST(cohort_definition_id AS VARCHAR(255)) as stratum_1,
cast(null as varchar(255)) as stratum_2, cast(null as varchar(255)) as stratum_3, cast(null as varchar(255)) as stratum_4, cast(null as varchar(255)) as stratum_5,
COUNT_BIG(subject_ID) as count_value
into @scratchDatabaseSchema@schemaDelim@tempAchillesPrefix_1700
from
@resultsDatabaseSchema.cohort c1
group by cohort_definition_id
;-- 1701 Number of records with cohort end date < cohort start date
select 1701 as analysis_id,
cast(null as varchar(255)) as stratum_1, cast(null as varchar(255)) as stratum_2, cast(null as varchar(255)) as stratum_3, cast(null as varchar(255)) as stratum_4, cast(null as varchar(255)) as stratum_5,
COUNT_BIG(subject_ID) as count_value
into @scratchDatabaseSchema@schemaDelim@tempAchillesPrefix_1701
from
@resultsDatabaseSchema.cohort c1
where c1.cohort_end_date < c1.cohort_start_date
;이 둘은 각각 cohort 당 환자수 (1700) 와 시작일이 종료일보다 빠르게 정의된 (잘못 정의된) cohort 의 수 (1701) 를 찾는 쿼리이다. 새로 생성한 Result Schema 보다는 Cohort 를 정의하는 등에 사용되는 Schema 를 지정해야 할 것 같다. (추후에 찾아서 다시 정리해보자.)
그 외에 아래와 같은 Warning Message 를 볼 수 있다.
Warning: Temp table name '#s_tmpach_****' is too long. Temp table names should be shorter than 22 characters to prevent Oracle from crashing.Oracle 과 관련된 Warning 메세지라 굳이 볼 필요가 없어서 sqlrender 에 PR 을 보냈으나, 아래와 같은 답변을 받았다.
No, the whole point of this message is to warn people that if someone did try to run the SQL on Oracle it would fail. The reason for using SqlRender is to write code that runs on all supported platforms. If you only want to write SQL that runs on your platform, don't use SqlRender.
실제로 Oracle 에서 실행하는 경우 해당 메세지와 관련하여 문제가 생길 것 같은데, 조만간 정리해서 Pull Request 를 보낼 예정이다. 이미 이슈는 등록되어 있다.
실행이 끝나면 resultsDatabaseSchema 로 입력한 schema 에 그 결과가 저장된다.
ATLAS 구동 포스팅 을 참고하여 그 내용을 Database 에 추가하고 tomcat 에서 webapi 를 reload 하면 ATLAS 에서 그 결과를 볼 수 있다.
INSERT INTO ohdsi.source_daimon (source_daimon_id, source_id, daimon_type, table_qualifier, priority) VALUES (3,1,2,‘results’,1);